
Scale out your Raspberry-Pi Kubernetes cluster to the cloud
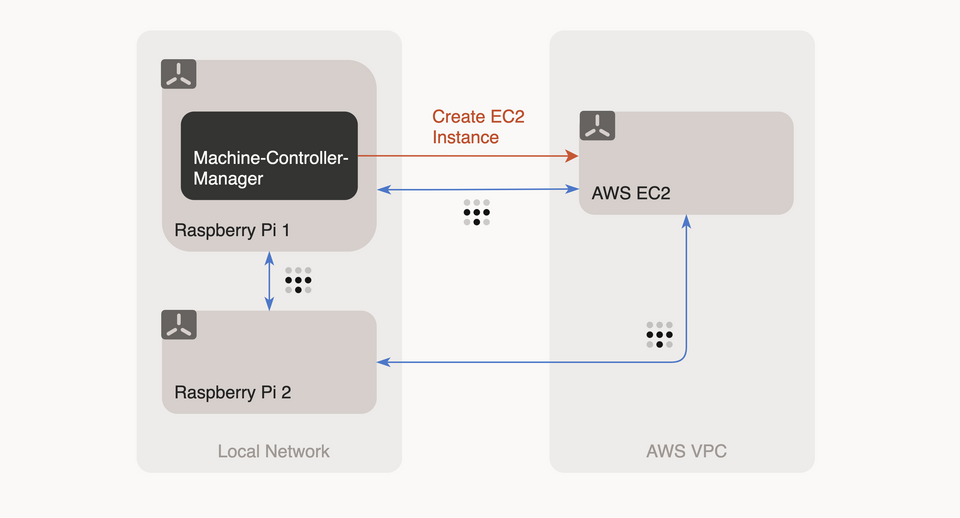
Using Gardener Machine-Controller-Manager and Tailscale to extend a local Raspberry-Pi K3s cluster with cloud instances.
Intro
Like a lot of Kubernetes enthusiasts, I grabbed a couple of Raspberry Pis, followed the instructions of Alex Ellis, and created a K3s cluster. I don't want to repeat this instruction here, Alex did a great job explaining how to prepare the Machines and a K3s setup cluster [1].
Then I found out about Tailscale [2]. A "no config" private networking solution based on Wireguard, allowing encrypted P2P communication between hosts, across NAT, firewalls, and other networking hurdles. I was intrigued, installed clients for iPhone, Mac, and some cloud machines and had some fun with it. It turned out to be quite reliable so that I started to connect my K3s Cluster nodes via Tailscale.
This allows entirely new possibilities: now I can make every machine that is capable of running Tailscale & K3s part of my cluster, no matter where it is actually located. Local Raspberry Pis and a Digital Ocean Droplet? No problem. Requiring an ARM A1 EC2 instance from AWS? It is a matter of 10min. I found out, that other people like Karan Sharma had the same idea and are also exploring the possibilities [3].
Problem Statement
Okay, so I can make any cloud instance part of my local cluster. But this still requires a bit of setup at the cloud vendor of your choice: at a minimum, you need to create a basic network infrastructure (VPC, subnets), create a VM (decide on an OS, setup Tailscale & K3s, assign Firewalls / Security Groups), oh, and please make sure it is running with a secure Runtime profile!
Karan Sharma solved this issue with a handful of Terraform code. While this is a valid option, it is not quite Kubernetes-like. Spawning additional VMs from within Kubernetes is a solved problem. So defining a Machine with a bit of YAML and having a controller taking care of machine creation & machine lifecycle should be possible.
Surprisingly so far no one seems to have done it in a K3s setup (at least I haven’t found anything). That is what this blog post is about.

What are the options?
Our requirements are simple: we need an operator that allows us to create vms of a specific cloud vendor. Those machines need to start Tailscale, join the Network, set up K3s, and join the cluster.
Kubermatic Machine Controller
The first time I saw Machine definitions as part of a Kubernetes Cluster was at KubeCon at the booth of the fine folks of Loodse. Their Kubermatic Machine-Controller supports various Cloud providers and is open source.
After a first analysis I figured out that it is lacking a bit of flexibility: The Machine Controller only allows spawning instances of a specific operating system. This alone is not a big issue, as probably 90% of considerable OSes are covered (even Flatcar!). The actual problem is, that it is heavily relying on Userdata to prepare the environment to join a Kubernetes Cluster. As we don’t want the instances to join a K8S but a K3s cluster, this is a problem. Also, it is not possible to overwrite or extend this Userdata. So if I wanted to go with Machine Controller I would have had to either prepare an OS Image (and overwrite some of MCs Userdata defaults) or see if I can extend the software in some way.
Gardener Machine Controller Manager
So I went on and found Machine-Controller-Manager (MCM), a core component of SAPs Gardener. While the name is a bit bulky, it couldn’t fit better. Because that’s what it does, in a very Kubernetes idiomatic way.
Machine Controller Manager makes use of 4 CRD objects and 1 Kubernetes secret object (for provider credentials) to manage machines. The Controller is the entity that watches for Machine-Sets (a group of machines = a VM backed by the cloud provider) or Machine-Deployments (a group of Machine-Sets; think of it as a Kubernetes Deployment). Part of their definition is a Machine-Class, which is a template that contains cloud provider-specific details to create our Machines (Machine Type, Region, Userdata, Security Groups, AMI Image, Network, Provider Credentials, etc.). Check the design docs for more info.
I like that MCM does not try to make assumptions of how the created machines need to look like. This allows us exactly what we want: configure a machine, spawn a machine, install some software on it, let it join the cluster.
It is possible, other options that are worth considering, but it turned out that MCM was exactly what I was looking for.
Setting up Machine Controller Manager
Before I was able to use MCM, I needed to create a linux/arm image. At the state of writing, MCM does not provide multi-arch builds, so I had to create my own.
Configure MCM
MCM needs permissions to create Cluster resources. It, therefore, expects a kubeconfig with sufficient permissions. For the sake of simplicity I here hand it my admin-config - please don’t do this!
$ kubectl create configmap mcm-config --from-file="config=~/.kube/config"
Afterward, we can reference it in a spec.volume:
volumes:
- name: kubeconfig
configMap:
name: mcm-config
Note: Gardener runs MCM in a “control-cluster” and lets it create VMs for foreign clusters. That's huge!
Configure the image: spec.containers.image: voigt/machine-controller-manager:v0.29.0-arm.
And starting the application in spec.containers.command with the following flag:
command:
- ./machine-controller-manager
- --v=2
- --target-kubeconfig=/.kube/config # Filepath to the target cluster's kubeconfig where node objects are expected to join
- --namespace=default # The control namespace where the controller watches for it's machine objects
MCM supports a couple of additional flags e. g. to control the VM lifecycle. You can find them here.
As I always want to be able to manage instances in my cluster I want to make sure, that MCM is scheduled on a node I always control. In my case, this is one of my Raspberries, so I configure a nodeSelector accordingly.
nodeSelector:
beta.kubernetes.io/arch: arm
node-role.kubernetes.io/master: true
Before the MCM can be deployed, it needs to be ensured that CRDs and Roles/Rolebindings are available as well. That's it. Apply the deployment and we have the controller running!
Setup the AWS environment
Unfortunately at this point the creation of an AWS environment still needs to be done outside of a Kubernetes Cluster. To fix this, I’m going to try the Terraform controller for Kubernetes soon.
In the meantime: I’m applying Terraform the old school way:
- credentials for a technical user including a sufficient set of IAM permissions
- a runtime role for the nodes
- Security Groups for our Nodes
- Outputs IDs for default VPC/Subnet
You can find the Terraform manifests in my repository. Especially noteworthy are the permissions required by MCM to control the EC2 lifecycle. I did my best to make this permission set as minimal as possible, please let me know if I can strip down permissions even further!
Preparing Userdata
The Userdata contains all necessary steps to install Tailscale and k3s clients, including joining the Tailscale network and the cluster. This is the script I use to spawn my nodes. Due to the lack of a proper secret store I currently write K3s auth key and the Tailscale auth key in plain text into the Userdata - I’m already looking for a more secure solution.
Joining the Tailscale network
The Tailscale clients join the network via pre-authenticated keys. This feature requires a pretty recent Tailscale version (at least 0.98-120), which is currently only available from the unstable branch. Preauthenticated keys can be generated and removed via the admin UI. Tailscale provides either "One-off Node authentication” (single-use keys) or Node Authentication (multi-use) keys. I’m currently relying on multi-use keys due to the lack of an API to obtain single-use keys. Be careful with multi-use keys!
For now, I also disabled key expiry, for my local Raspberry Pi nodes. I don’t think this will be necessary for the cloud instances spawned by MCM: If the key expires, the node will become NotReady and eventually leave the cluster. A new node will be provided by MCM with a fresh key. This means MCM nodes will be recycled at least every six months.
$ tailscale up --authkey tskey-<random-number>
Tailscale feature request: I’d love to set a lower than 6 months TTL for those keys.
Once Tailscale is up, the Node has network connectivity to the K3s API server, so it can join the cluster.
Preparing a Secret
The Secret contains three crucial items: AWS Access Key ID, AWS Access Key Secret, and our Userdata. I do not store this secret manifest in my git repository, I create it on the fly like this:
$ kubectl create secret generic aws-secret \
--from-literal="providerAccessKeyId=$(cat environment/aws/credentials | head -n 1)" \
--from-literal="providerSecretAccessKey=$(cat environment/aws/credentials | head -n 2 | tail -n 1)" \
--from-file="userData=deployments/kube-system/machine-controller/userdata"
Please keep in mind, that Kubernetes stores secrets base64 encoded, in plain text. You might want to think about encrypting this secret as it contains AWS Credentials and (in my case) the K3s Node Token as well as the Tailscale Authkey! I’m currently considering sealed secrets for this case.
Configure a Machine-Class
Now we have all requirements set up to define our Machine-Class. This is my example machine-class manifest for AWS, which contains an explanation of the most important configuration keys. Depending on your target cloud provider, you need to use a different spec. The MCM repository contains further examples!
I use an Ubuntu 18.04 AMI image (ami-0e342d72b12109f91) and let the instances spawn in a subnet of my default VPC in eu-central-1. Via spec.keyName I specified an SSH key pair - this can be handy to debug instances in case they do not spawn properly.
Configure a Machine Deployment
The final step is to tell MCM to create a Machine of kind AWSMachineClass, named “test-aws”. We do so by creating a Machine Deployment and referencing our just created Machine-Class.
spec:
class:
kind: AWSMachineClass
name: test-aws
The rest of the Deployment spec looks pretty similar to a Pod Deployment spec. You can define a replica count, update strategies… It feels quite familiar.
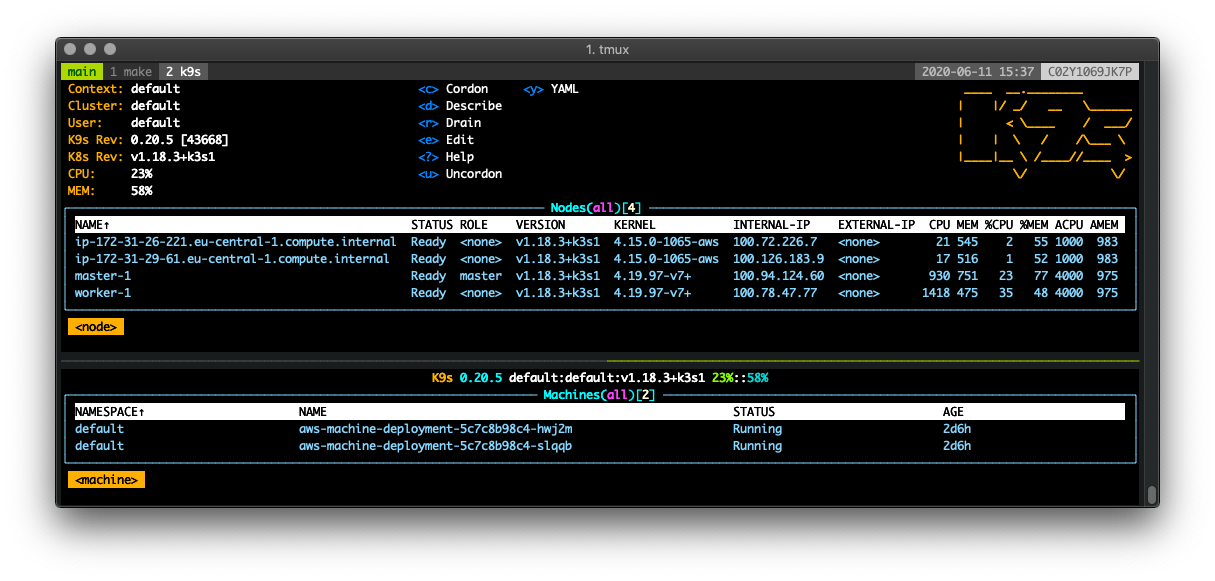
What should I say? Done correctly MCM will create (in my case) two brand new EC2 instances that automagically join our cluster.
Issues I faced
While the idea is easy, I still spend way too much time setting everything up. I came across two major issues that cost me a significant amount of time...
Pending Nodes
While machines reliably joined the cluster, the MCM at first did not consider them as “Ready” and terminated them after some time. The machine objects' status was pending, even though the node objects status was ready.
Kudos to Hardik from the MCM team, who kindly helped me to explain the inner workings of MCM: turns out, MCM identifies instances by two parameters: spec.providerID and spec.name. Depending on the provider implementation those parameters must follow a specific pattern - in the example of the AWS provider, my problem looked like the following:
<node>.spec.providerID: k3s://ip-172-31-16-232
<machine>.spec.providerID: aws:///eu-central-1/i-00728a20e15067c15
<node>.spec.name: ip-172-31-16-232
<machine>.metadata.labels.node: ip-172-31-16-232.eu-central-1.compute.internal
Luckily this issue was easy to fix: starting the k3s agent with --kubelet-arg="provider-id=aws:///${EC2_REGION}/${EC2_INSTANCE_ID}" solved the providerID issue. Furthermore K3s allows to change the name that an instance uses to join the cluster, which fixed the second issue: K3S_NODE_NAME="${EC2_INTERNAL_DNS}".
Both, the internal DNS name as well as the EC2 instance ID can be obtained by the EC2 metadata service. Setting those parameters are usually a cloud controllers job (read more here). As we don’t have one, we need to take care of it on our own.
Inter-pod communication of pods on different hosts
After nodes joined reliably, I figured out a connectivity issue: while pods on the same host were able to communicate just nicely, pods on a different host could not reach each other.
It didn’t take too long to understand, that the overlay network (flannel) was trying to access the pods via the standard interface (eth0) and did not use the tailscale interface (tailscale0).
I found an option to tell flannel to use a specific interface: --flannel-iface=tailscale0, but this still wouldn’t fix my problem. My research revealed, that there are issues with K3s and flannel in a specific setup, so I spend a lot of time learning.
It took me two more evenings of frustration to realize I had another problem: my Raspberry Pis where running on a too old Tailscale version.
Finally, the network setup looks something like this:

Remaining Issues
Most of the setup runs smoothly now. Though, I figured out an annoying thing:
Destroyed nodes are still in the list of Tailscale clients
While I can add new Tailscale clients automagically, there is (to my knowledge) no API to remove a client from the network. This currently leaves me with manually removing deprecated machines from the admin panel.
Tailscale feature request: add a disconnect command to the client :)
Outro
I’m now able to add and remove nodes of various cloud providers to my local Kubernetes cluster - all via configuration. Nothing stops me from creating a cluster utilizing machines from AWS, Azure, and GCP. Tailscale paves the way to make the networking effort almost frictionless. However, this whole exercise revealed a caveat: due to the lack of a multi-cloud capable cloud controller, it is not possible to create cloud resources like load balancers or volumes from within the cluster.
Furthermore, this is the proof, that Gardeners Machine-Controller-Manager is quite a flexible piece of software and can be used independently of the rest of the Gardener stack. Unfortunately, it is unlikely, that the project will maintain a linux/arm release.
At the time of writing, MCM supports AWS, Azure, Alibaba Cloud, GCP, Openstack, Packet, and vSphere. I was actually looking for Digital Ocean support, which is not covered yet. But adding another provider seems to be pretty straight forward - maybe a next project, we will see. Just recently there has been a PR merged, that aims to allow out-of-tree providers. With this feature, it wouldn’t even be necessary to adjust MCM itself, but use it as an interface instead.
References:
[1] - https://blog.alexellis.io/test-drive-k3s-on-raspberry-pi/
[2] - https://tailscale.com/
[3] - https://mrkaran.dev/posts/home-server-updates/