
Writing a Tech Newsletter: One Year of NativeCloud.dev

It has been more than 12 months now that we (almost regularly) collect and annotate the cloud-native universe's news. We take this as a reason for some retrospection.
Starting with some statistics
In 2020 we had:
- 15.7k unique visitors 21.8k page views (with a peak of 3.165 visitors / 4.626 page views in August)
- Avg. Time on Site: 02:03, Bounce Rate: 84%
- Newsletter: 43 (most views had CNN-21 with 1,024 / 788 uniques)
- Articles (non-newsletter): 5 (over all responsible for 8.114 views / 7018 uniques)
- 61 Newsletter Members (in the period August 10th until 31st of December)
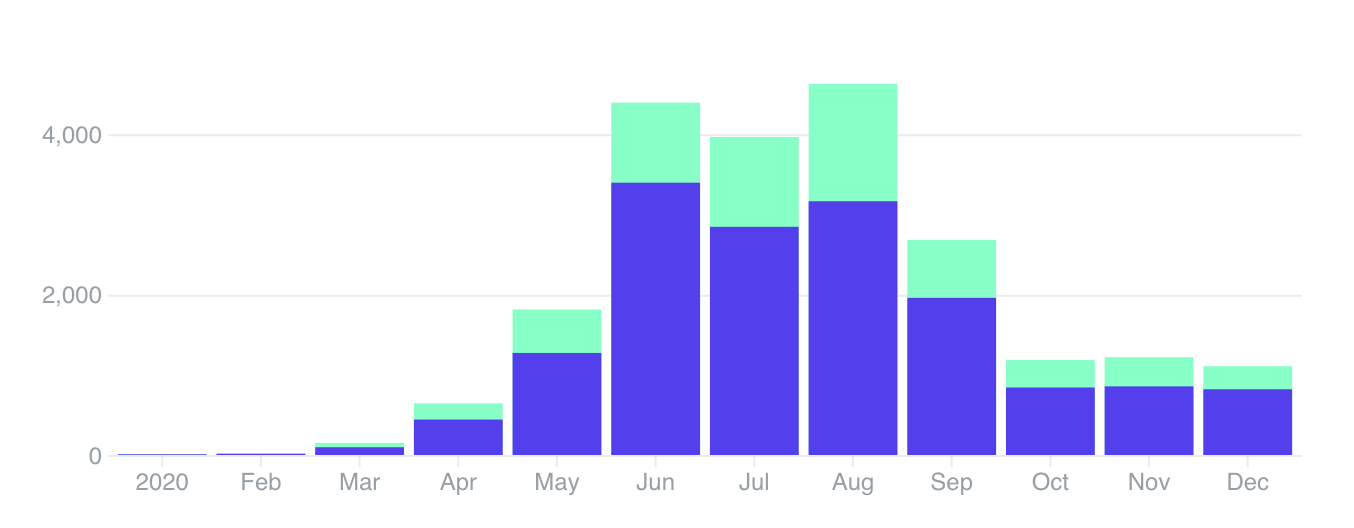
We started this website in February. Back then, we didn't do any "marketing". In May, we started sharing our articles via the usual channels such as Facebook, Twitter, and Reddit.
We had a great increase in engagement for the first five months that we could maintain for roughly three months. Jun-Aug performed exceptionally well, because additionally to our Newsletter, we also had "original" content in the form of longer articles.
Social Media
Facebook usually brought us the most attraction - it was responsible for roughly ~50% of the traffic. In September, something strange happened: the engagement stopped from one week to another. Almost no hits were coming from Facebook anymore. We assume that Facebook changed its Groups' algorithm, as the engagement with our posts dropped rapidly.
Twitter. While I personally feel that most people interested in our content are also active on Twitter (for us), it does not help advertise a new article. To be relevant on Twitter, we would need to post (way more) frequently. Posting the link to our newsletter once a week is flushed down into the Twitter aether within minutes.
From time to time, we also distribute a link to our new issue on Reddit. Depending on the headline (buzz words) we use, the posts perform well or not at all.
Channels of Distribution
In October, we started to publish the newsletter not only via this website but also via email. People now can subscribe to our mailing list, which will forward every new issue directly to their mailbox.
We see this as a service to our readers, giving them the choice of how to consume our content: Website, RSS, or Email. We realize that this also means that we don't have the full visibility of how many users are actually consuming our content, as we don't gather any statistics about RSS or email consumption.
Speaking of visibility: we are convinced that tracking our users is not a good habit. Therefore we do not rely on any cookies to gather website analytics.
How do you find news-worthy links?
We have different sources for news
- Community (like CNCF/Kubernetes slack, Twitter)
- Feed readers (Feedly fan here!) are full of blogs with relevant content
- Contributions by our readers (admittedly not too much)
What's the process of editing?
As the format of the newsletter is pretty static, we started to automize as much as possible. We noticed that we are formatting the same headlines and bullet points repeatedly, even though we are following a strict template.
That's why we went over collecting Links, Title and Descriptions in a Google Spreadsheet. Having the data in such a structured format allows us to generate the newsletter following a defined template. All realized in a few lines of Google Apps Script.
This enables the following process:
- Having a link, we either directly dump it into our Google Spreadsheet or send it to our Telegram Bot, which automagically appends the lInk to the same sheet
- After collecting all the links in a Spreadsheet, we are automagically fetching metadata like title and description (if possible), utilizing Google Spreadsheets IMPORTXML function. This reduces the amount of copy/pasting title information. It is less error-prone and sometimes reduces the effort to find a description to a given website (though not all websites support meta information - looking at you, Medium!).
- The majority of automatically fetched information can not be used 1:1. This is where the actual curation and analysis are happening. Formulating title and a description and, most importantly, decide whether the given link should be part of the final Newsletter.
- Once we are done with editing and curation, we are generating the article using our templating function. This prints out properly formatted Markdown, ready to use for Ghost (our blog engine).
- As both of us are no native English speakers, we tend to make spelling or grammatical mistakes. This is why we first process the text via Grammarly before we finally publish the article.
How long does it take?
This is hard to say and varies from week to week, depending on how many articles we find newsworthy. Overall it is probably between four to six hours each of us dedicating each week, including reading and collecting links.
What about costs?
Hosting: The website runs on a Digital Ocean Droplet with some additional storage. Over the year, this makes ~12*(5€+10€)=180€. But costs are a little blurred here, as the droplets capacity is by far not exhausted — That's why I operate some other services on the same droplet.
Domain: The domain is registered via inwx.de and is 15,00€ per year. Name server via Cloudflare ("for free"). SSL via letsencrypt.
So over the year, the whole website is about 200€.
Considering our very static content, we could be a lot cheaper by going with a static website and throwing it over to Netlify. But, you know... Things that are working are rarely changed ;)
That's a lot of time and money invested. Why?
As consultants, we have to follow the developments around Kubernetes and the cloud world closely. This means reading news, proof of concepts, tutorials, articles are anyways part of our job. NativeCloud.dev is one way to separate the better from, the lesser good websites out there and archive them for later reference.
What's next?
From all of the links we weekly collect, only a tiny subset reaches the end product. We thought about "recycling" and sharing them via Twitter. Not all of the links we share will be relevant in a few months. But there is a considerable amount of (more or less) timeless articles that would be worth sharing from time to time. This is easily achievable with a bot without further effort. The first experiments were quite successful so far.
Apart from that, we are satisfied with the current state. Currently we are not monetizing this hobby project, so we have no pressure to "grow" our audience. This leaves us some mental freedom of being able to stop anytime.
Nevertheless, it is nice that there are people outside reading our curation.
Photo by Nick Morrison on Unsplash